Using AI to Help Physicians Take Notes for Electronic Health Records
Marie Donlon | August 23, 2018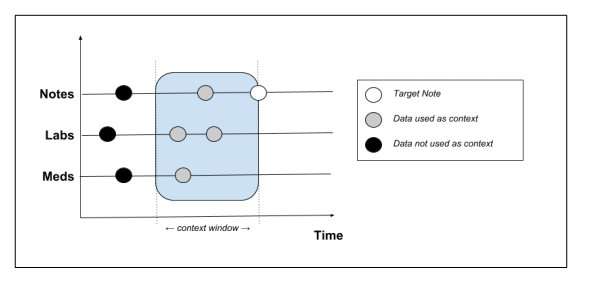 Schematic showing which context data is extracted from the patient record. Source: Peter LiuBased on estimates from a 2016 study, for every hour spent with a patient, physicians will spend two hours writing and entering notes into electronic health record (HER) systems. Thanks to artificial intelligence that process might soon become automated, which would free doctors up for more important tasks.
Schematic showing which context data is extracted from the patient record. Source: Peter LiuBased on estimates from a 2016 study, for every hour spent with a patient, physicians will spend two hours writing and entering notes into electronic health record (HER) systems. Thanks to artificial intelligence that process might soon become automated, which would free doctors up for more important tasks.
The system, developed by Google Brain Researcher Peter Liu, is a new language modeling task capable of predicting new patient notes based on an analysis of patient medical records. The data — demographics, medications, past notes and laboratory measurements — culled from such notes was compared to generative models trained using the MIMIC-III (Medical Information Mart for Intensive Care) EHR dataset.
"Assistive-writing features for notes, such as auto-completion or error-checking, benefit from language models," Liu wrote in his paper. "The stronger the model, the more effective such features would likely be. Thus, the focus of this paper is in building language models for clinical notes."
Current methods for reducing the amount of time physicians spend on taking notes might involve dictation services or assistants who write up the notes. However, the team believes that the AI tools might help physicians tackle the issue, thereby eliminating the need and expense of additional staff and services.
To develop the tools, Liu used two language models, called the transformer architecture and transformer with memory-compressed attention (T-DMCA), and trained them on the MIMIC-III dataset.
"We have introduced a new language modeling task for clinical notes based on EHR data and showed how to represent the multi-modal data context to the model," Liu explained in his paper. "We proposed evaluation metrics for the task and presented encouraging results showing the predictive power of such models."
Liu found that the models accurately predicted a significant amount of the physician note content. However, more sophisticated spell checking and auto-complete features would need to be developed in the future to further ease the administrative work. Likewise, Liu acknowledges that challenges still need to be overcome before using the models on a larger scale.
"In many cases, the maximum context provided by the EHR is insufficient to fully predict the note," Liu explained in his paper. "The most obvious case is the lack of imaging data in MIMIC-III for radiology reports. For non-imaging notes we also lack information about the latest patient-provider interactions. Future work could attempt to augment the note context with data beyond the EHR, e.g. imaging data, or transcripts of patient-doctor interactions. Although we discussed error correction and auto-complete features in EHR software, their effects on user productivity were not measured in the clinical context, which we leave as future work."
For more on Liu’s work, go to the article Learning to Write Notes in Electronic Health Records published on arXiv.




This is an interesting approach. But I'm still waiting when AI would help me to write a college assignment)) This service https://writemypaper