The Birth of the Data Engineer
Jonathan Fuller | October 26, 2017The sheer amount of data floating about in the world is growing at an exponential rate. Sensors — like those found in smartphones, wearable devices and IoT components — are constantly compiling data about energy usage, fitness activity and more. This data, if properly structured, is extremely useful to applications as diverse as product marketing and military intelligence.
It’s probably no surprise, then, that data science and data engineering are also growing. But what’s the difference, if any, between these two fields, and how does one become a data engineer?
What is Data Engineering?
It’s almost impossible to discuss data engineers without first defining data science and data scientists. Even the terms “data scientist” and “data engineer” are fluid and may vary widely depending on the organization, but it’s possible to make generalizations about both roles.
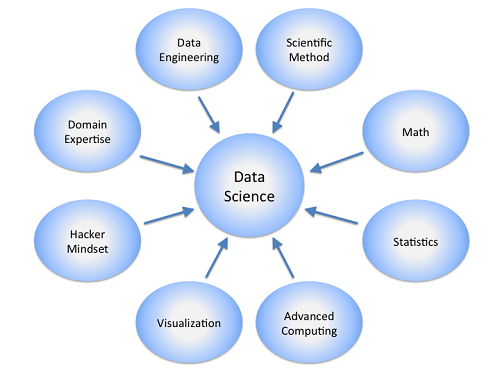 The many disciplines related to data science, including data engineering. Source: Calvin.Andrus / CC BY-SA 3.0Data science generally uses scientific methods to extract insights from either structured or unstructured data. Data scientists attempt to explain and predict complex behaviors through models based on math, statistics and machine learning. They then build those models into software programs. Because they need the ability to conduct scientific research and build advanced models, data scientists tend to be more academic, with backgrounds in the hard sciences or computer science.
The many disciplines related to data science, including data engineering. Source: Calvin.Andrus / CC BY-SA 3.0Data science generally uses scientific methods to extract insights from either structured or unstructured data. Data scientists attempt to explain and predict complex behaviors through models based on math, statistics and machine learning. They then build those models into software programs. Because they need the ability to conduct scientific research and build advanced models, data scientists tend to be more academic, with backgrounds in the hard sciences or computer science.
Data engineers design and build data architectures for ingesting, processing and exposing data for large data-intensive applications. They typically have a less academic background and may hold degrees in software engineering or computer science.
In an ideal organization working with big data, data scientists and data engineers work in tandem. Data scientists run experiments and develop algorithms to gain insight into datasets. Data engineers essentially manage that data and make sure it flows to where it needs to go. They also build the underlying systems that allow the data scientists to perform their work.
Job Description and Work
Data engineers usually perform one or more of the following activities in their organization:
- Data warehousing: Engineers work to consolidate an organization’s heterogeneous data into a single storage solution. Data scientists can then run complex queries on a single source.
- Designing and maintaining ETL pipelines: Extract, Transform, Load (ETL) pipelines are similar to data warehouses. ETL essentially involves moving data from an initial source to a different location.
- DevOps: Data engineers may need to work with the raw storage nodes to install software and other tools. In smaller organizations, these tasks typically fall to the data engineers more often. Large organizations usually define their own DevOps job descriptions.
- Infrastructure tools: Data engineers may also maintain or modify infrastructure tools; as in DevOps, these tasks typically fall to data engineers in smaller companies.
- Assisting data scientists: Data engineers may also cross over into the realm of data science, running statistical experiments and implementing machine learning. In a small organization with a single data engineer, the position may function as a data scientist as well.
While it’s clear that there’s no single job description for a data engineer, those interested in the field should possess a certain skill set:
- A strong understanding of core computer science concepts
- The ability to build and design large-scale applications, end to end
- Knowledge of the pros and cons of relational and noSQL databases
- An understanding of distributed computing
- The ability to operationalize a working model and push model specifications into real-world engines
A Data Engineer’s Role in the IoT
Data engineers will likely have an expanded role in the ever-developing IoT data stream. In its present state, deployment and configuration no longer cause problems for the IoT. Most connected devices can be set up and operating in a matter of minutes, but it’s the data itself now posing a challenge. In addition to the size of the data, the diverse nature of modern data useful to analysis is more of a problem. This is where data engineering becomes necessary.
 Source: Matthew (MWF) / CC BY-SA 3.0In a mature system, IoT data flows from the sensors into a massive “data lake” consisting of all kinds of data: structured, semi-structured, unstructured, transformed, raw, binary, etc. Data lakes are usually powered by a framework like Hadoop. High-value data will move out of the lake and into a data warehouse, where it can be enriched with other data. This new set is used to create useful models and is also piped to different applications and analytics engines that run on IoT data. These applications then create useful data, which flows back to the enterprise warehouse.
Source: Matthew (MWF) / CC BY-SA 3.0In a mature system, IoT data flows from the sensors into a massive “data lake” consisting of all kinds of data: structured, semi-structured, unstructured, transformed, raw, binary, etc. Data lakes are usually powered by a framework like Hadoop. High-value data will move out of the lake and into a data warehouse, where it can be enriched with other data. This new set is used to create useful models and is also piped to different applications and analytics engines that run on IoT data. These applications then create useful data, which flows back to the enterprise warehouse.
A complex data supply chain of this magnitude would be impossible without data scientists and data engineers. They work to handle ever-increasing amounts of data from increasing sources from all over the world at never-before-seen volumes to make sure the data is processed, archived, pruned or shared as necessary.
Data engineering is an exciting field on the cutting edge of computing. Data-driven decision making is important to most modern businesses, so the opportunities and challenges of data engineering show no signs of slowing anytime soon.


